Claude Opus 4.6 vs Gemini 3.1 Pro: Who Wins the 1 Million Token Context War? (2026)

Every frontier model now claims a 1 million token context window. Google had it first with Gemini. Anthropic caught up in March 2026. OpenAI is there too. So the question is no longer "who has the biggest window?" The question is: what does the model actually do with 1 million tokens of context?
I've been using Gemini's 1M context since Gemini 3 Pro launched. I used it daily for journal analysis, long document retrieval, and personal knowledge management. The context window was Gemini's killer feature. Then Claude Opus 4.6 got 1M tokens on March 13, 2026, and I switched my primary workflows to it within a week.
But having 1M tokens doesn't mean much if the model can't reason, follow instructions, and take actions reliably inside that window.
TL;DR#
- 1M tokens is table stakes in 2026. Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.4 all have it. The differentiator is what happens inside the window.
- Claude Opus 4.6 leads on agentic handling. Multi-step tool use, self-correction, and instruction-following across massive context. Even at 2.5x the price, it's the better agent.
- Gemini 3.1 Pro wins on multimodal, but the price gap is smaller than you think. At 1M context, Gemini actually charges $4/$18 (tiered pricing above 200K tokens). Only 20% cheaper than Claude's flat $5/$25.
- Gemini 3.1 Flash-Lite is the sleeper pick. $0.25/$1.50 with 1M context. Not just for summarization. It handles agentic tasks in high-volume scenarios like telecom and customer service.
- The smart play: route between all three. Flash-Lite for volume, Gemini 3.1 Pro for multimodal, Opus for anything where reasoning quality matters.
Why 1 Million Tokens Is the New Baseline#
How Much Fits in 1 Million Tokens?#
To put that in perspective, 1 million tokens is roughly:
What Fits in 1 Million Tokens
| Content Type | Approximate Amount |
|---|---|
| English words | ~750,000 words |
| Book pages | ~3,000 pages |
| Full novels | ~10-12 novels |
| Lines of code | ~60,000-80,000 lines of code |
| Conversation turns | ~10,000+ exchanges |
| Legal contracts | ~500+ standard contracts |
| Support tickets | ~2,000+ full tickets with history |
That's an entire codebase. Six months of customer conversation history. A full litigation discovery set. This isn't about reading longer PDFs. This is about giving models enough context to make informed decisions across massive information sets.
If you're new to thinking about context types and how they affect AI output, I covered the framework in 5 Essential Context Types for AI.
What Changed on March 13, 2026#
Anthropic made the 1M context window generally available for Claude Opus 4.6 and Sonnet 4.6 at standard pricing. No beta. No waitlist. No long-context premium.
This is the part that matters: a 900K-token request costs the same per-token rate as a 9K one. Opus 4.6 bills at $5/$25 per million tokens whether you're sending 10K tokens or 950K tokens. That's not how it used to work. Previously, long context meant premium pricing. Not anymore.
What Actually Separates Models at 1M Tokens#
The window size is settled. What separates models is:
- Retrieval quality at scale. Can the model find and use information buried deep in context?
- Reasoning quality at high token counts. Does the model get dumber as context grows?
- Agentic capability inside large context. Can it plan, use tools, and self-correct while maintaining awareness of the full window?
That third point is where Claude Opus 4.6 pulls ahead. And it's why I switched.
Claude Opus 4.6: The Agentic Powerhouse With 1M Context#
Claude Opus 4.6
Developer: Anthropic
Anthropic's most capable model. 1M context window (GA March 2026) with server-side context compaction for infinite conversations. Leads agentic benchmarks across the board.
Specifications
Why Agentic Handling Matters More Than Context Size#
Most comparisons miss this. A 1M context window means nothing if the model loses track of its instructions at 400K tokens. Or if it starts hallucinating tool calls. Or if it gets distracted by irrelevant content in the context, like Gemini did in my agent pipeline test.
The benchmarks tell a nuanced story. Unless noted, numbers below are from Google DeepMind's official model card using the same harness for apples-to-apples comparison:
- SWE-bench Verified: Claude 80.8% vs Gemini 80.6%. Basically tied on autonomous bug fixing.
- Terminal-Bench 2.0: Gemini 3.1 Pro at 68.5%, Claude Opus 4.6 at 65.4% (same Terminus-2 harness). Credit where it's due: Gemini leads on terminal workflows.
- τ2-bench (agentic tool use): Tied. Telecom: both 99.3%. Retail: Opus 91.9%, Gemini 90.8%.
- MRCR v2 (8-needle at 128K): Tied. Gemini 84.9%, Claude 84.0%.
- MRCR v2 (8-needle at 1M): Gemini drops to 26.3% (Google-reported). Anthropic claims Claude holds at 76% (source), but this hasn't been independently verified at 1M.
On coding and standard agentic tasks, these models are neck and neck. The big question is what happens at 1M context. Google's own data shows Gemini collapses from 84.9% to 26.3% on retrieval. Anthropic claims Claude barely degrades. Even with that caveat, the direction strongly favors Claude for large-context work.
I've tested this extensively with Claude Code. Loading entire codebases into context, running multi-file refactors, debugging complex agent pipelines. Opus holds the thread. It knows what it was doing 600K tokens ago. That's not something you take for granted.
What Compaction Means for Infinite Conversations#
Claude Opus 4.6 includes server-side context compaction. When the conversation approaches the 1M token limit, the system automatically summarizes earlier context to make room for new information. This means effectively infinite conversations. You don't hit a wall and start over. The model gracefully degrades older context while preserving the most relevant information.
No other model does this at the infrastructure level. With Gemini, when you hit the limit, you hit the limit.
A Warning for Claude Code Users#
Here's the catch nobody talks about: 1M context burns through your subscription limits fast. Even on the $200/month Max plan (20x usage), a single long session with Opus at high context can eat a significant chunk of your weekly allowance. You're sending 500K-900K tokens per request instead of 50K-100K. That's 10x the consumption per interaction.
I've hit the weekly limit mid-week more than once since switching to 1M context. The effort level settings help, but you need to be intentional about when you actually need the full context window vs. when a smaller scope will do. Don't load your entire codebase for a one-file fix. Save the 1M context for tasks that genuinely need it: large refactors, cross-file debugging, architecture decisions.
Where Opus Shines#
- Complex agentic workflows. Multi-step tool use with planning and self-correction. My Opus vs Codex comparison showed this clearly.
- Full codebase analysis. Load 60,000+ lines of code and get meaningful cross-file reasoning.
- Decision-making over large history. Feed it 6 months of customer data and ask it to personalize a response. It actually uses the full history, not just the last few messages.
- Deep reasoning at scale. The quality doesn't degrade noticeably at 800K+ tokens. That's rare.
Gemini 3.1 Pro: Cheaper 1M, Strong Multimodal#
Gemini 3.1 Pro
Developer: Google
Google's flagship model with native 1M token context and multimodal processing across text, video, audio, and images. Cheapest cached input among top-tier models.
Specifications
Important pricing detail: Gemini 3.1 Pro uses tiered pricing. The $2/$12 rates only apply for prompts under 200K tokens. Once you cross 200K, input doubles to $4 and output jumps to $18. For a 1M context article, the actual cost is $4/$18, not $2/$12. This makes the gap with Claude ($5/$25) much smaller than it looks at first glance.
Where Gemini Shines#
Gemini 3.1 Pro is a genuinely strong model. For the right use cases, it's the better choice:
- Native multimodal at 1M scale. Feed it hours of video, thousands of images, audio files. Claude can't do that.
- Budget-friendly for short-context work. At $2/$12 for prompts under 200K, it's genuinely cheap. The $0.20 cached rate is excellent for chatbot-style apps where you resend conversation history.
- Bulk document processing. Compliance scans, contract reviews, content classification across massive document sets. When you need to process volume, Gemini's pricing makes the math work.
- Long-document analysis. Single-turn tasks over huge inputs. Summarization, extraction, Q&A across thousands of pages.
Where It Falls Behind#
Agentic follow-through. I've written about this in detail. Put Gemini 3.1 Pro inside a multi-step agent pipeline and things get unpredictable. It gets distracted by content in the context. It abandons the original task. It doesn't self-correct as reliably.
For single input/output tasks, Gemini is excellent. For autonomous agents that need to maintain intent across dozens of tool calls inside 500K+ tokens of context, Claude is in a different league.
The max output of 65K tokens (vs Claude's 128K) also matters for agentic workflows that require long, structured outputs.
Stay ahead of the curve
Find out which LLM is cheapest for your use case — I test new models as they launch
The Budget 1M Option: Gemini 3.1 Flash-Lite#
Nobody talks about this model enough.
Gemini 3.1 Flash-Lite
Developer: Google
Google's most cost-efficient model with full 1M context. 363 tokens/sec. Built on Gemini 3 Pro architecture. Viable for high-volume agentic tasks at massive scale.
Specifications
At $0.25 per million input tokens, you can process 1M tokens of context for a quarter. Cached? Two and a half cents. That's practically free.
Not Just Lightweight. Agentic at Scale Too.#
The obvious use cases are summarization, extraction, and classification over huge documents. But Flash-Lite is more capable than people give it credit for.
Think about telecom customer service. You need to process thousands of customer interactions per hour, each with a full conversation history loaded into context. You need the agent to route, respond, and escalate. You don't need Opus-level reasoning for every call. You need a model that's fast, cheap, and good enough. Flash-Lite at 363 tokens/sec with 1M context fits that perfectly.
Same for insurance claims processing, support ticket triage, or any high-volume agentic pipeline where cost per call matters more than peak reasoning quality.
The Smart Routing Play#
The real architecture isn't "pick one model." It's:
- Flash-Lite for high-volume, structured agentic tasks and preprocessing (extraction, summarization, classification)
- Gemini 3.1 Pro for multimodal processing and moderate-complexity analysis
- Claude Opus 4.6 for complex reasoning, critical agentic workflows, and anything where the output has to be right
If you want to understand how to identify which model fits which task, I covered that framework separately.
Head-to-Head: Benchmarks and Agentic Performance#
1M Context: Claude Opus 4.6 vs Gemini 3.1 Pro vs Flash-Lite
| Benchmark | Claude Opus 4.6 | Gemini 3.1 Pro | Flash-Lite | Winner |
|---|---|---|---|---|
| MRCR v2 (8-needle, 128K) | 84.0% | 84.9% | N/A | Tied |
| MRCR v2 (8-needle, 1M) | 76%* | 26.3% | 60.1% | Claude* |
| SWE-bench Verified | 80.8% | 80.6% | N/A | Tied |
| Terminal-Bench 2.0 | 65.4% | 68.5% | N/A | Gemini |
| τ2-bench (Retail) | 91.9% | 90.8% | N/A | Tied |
| τ2-bench (Telecom) | 99.3% | 99.3% | N/A | Tied |
| Native multimodal | No (vision only) | Yes (video, audio, images) | Yes | Gemini |
| Max output tokens | 128,000 | 65,536 | 65,536 | Claude |
| Context compaction | Yes | No | No | Claude |
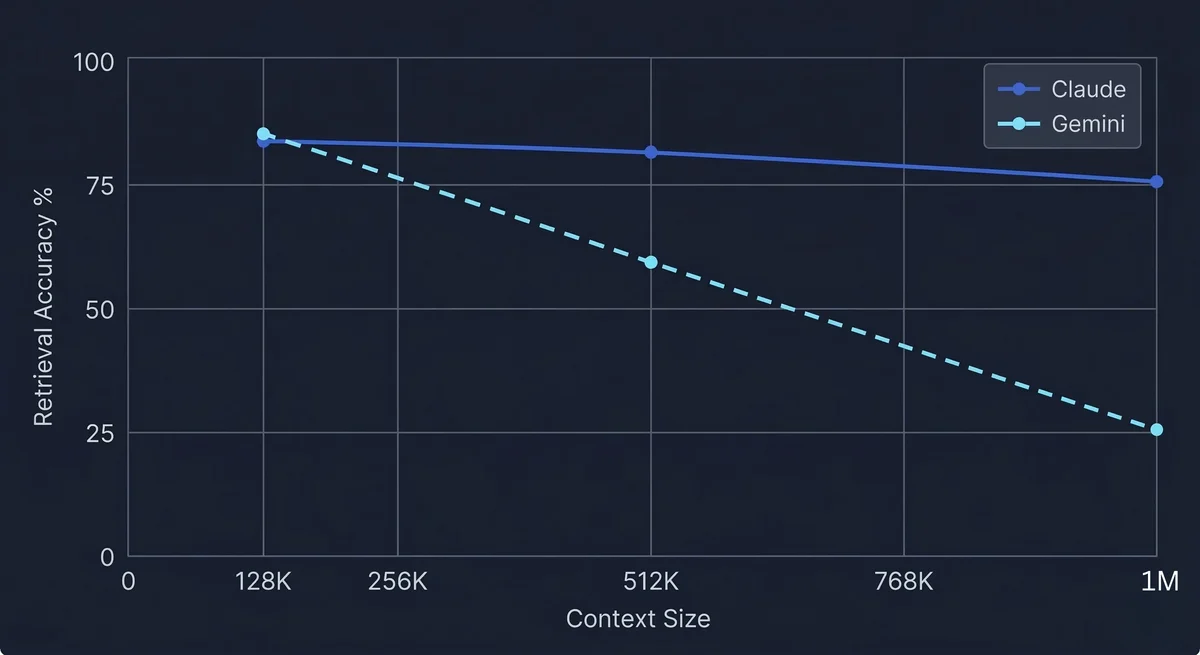
Retrieval Quality: The Number That Matters#
MRCR v2 (Multi-needle Retrieval and Contextual Reasoning) hides 8 needles across the context window and tests whether the model can find and reason about all of them.
At 128K tokens, both models are basically tied: Gemini 84.9%, Claude 84.0%. This is from Google's own model card, same evaluation methodology, apples-to-apples.
At 1M tokens, things diverge dramatically:
- Gemini 3.1 Pro: 26.3% (Google-reported on their model card)
- Claude Opus 4.6: 76% (Anthropic-reported; Google's card shows "Not supported" since they tested before Claude's 1M went GA)
A caveat: these 1M numbers come from different sources. Google reported their own, Anthropic reported their own. No independent third party has verified both at 1M on the same harness. Take the exact gap with a grain of salt.
That said, the direction is clear. Gemini drops from 84.9% to 26.3% when going from 128K to 1M — a 69% collapse. Anthropic claims Claude only drops from 84% to 76%. Even if the real number is somewhat lower, the degradation pattern is dramatically different.
Interestingly, Flash-Lite scores 60.1% at 1M on MRCR v2 — outperforming Gemini 3.1 Pro. If you need cheap 1M retrieval, Flash-Lite is the better Gemini option.
Coding and Agentic Benchmarks: Neck and Neck#
On SWE-bench Verified, it's essentially a tie: Claude 80.8%, Gemini 80.6%. On Terminal-Bench 2.0, Gemini edges ahead at 68.5% vs 65.4% (same harness). On τ2-bench, which tests real agentic tool use in retail and telecom scenarios, they're practically identical.
So why do I still prefer Claude for agentic work at 1M context? Because these benchmarks run on clean, isolated tasks with moderate context sizes. In production agent pipelines with 500K+ tokens of context, Gemini still gets distracted. That MRCR v2 gap (76% vs 26.3% at 1M) shows up as real-world reliability when context is large, not just a leaderboard number.
Context Rot: What Happens at 800K+ Tokens#
Both models degrade at extreme context lengths, but at very different rates. The MRCR v2 results tell the story: at 128K, both score ~84-85%. At 1M, Gemini drops to 26.3% — a 69% collapse per Google's own data. Anthropic claims Claude only drops to 76%, though independent verification at 1M is still pending. Either way, the compaction feature means Claude never hits a hard wall. Gemini does.
What 1M Tokens Actually Costs: A Real Pricing Breakdown#
1M Context Window: Full Pricing Comparison
| Model | Context | Input/1M | Output/1M | Cached Input/1M | SWE-bench | Value Score ⬇️ |
|---|---|---|---|---|---|---|
| 1 Claude Opus 4.6 | 1M | $5.00 | $25.00 | $0.50 cached | 80.8% | N/A |
| 2 Gemini 3.1 Pro | 1M | $2-4* | $12-18* | $0.20-0.40* | 80.6% | N/A |
| 3 Gemini 3.1 Flash-Lite | 1M | $0.25 | $1.50 | $0.025 cached | N/A | N/A |
Cost Per Request at Different Context Sizes#
What you actually pay per request at different context sizes (input only, excluding output):
Cost Per Request by Context Size (Input Only)
| Context Size | Opus 4.6 | Opus (cached) | Gemini 3.1 Pro | Gemini (cached) | Flash-Lite | Flash-Lite (cached) |
|---|---|---|---|---|---|---|
| 100K tokens | $0.50 | $0.05 | $0.20 | $0.02 | $0.025 | $0.0025 |
| 500K tokens | $2.50 | $0.25 | $1.60 | $0.16 | $0.125 | $0.0125 |
| 1M tokens | $5.00 | $0.50 | $3.60 | $0.36 | $0.25 | $0.025 |
A full 1M context request on Flash-Lite with caching costs 2.5 cents. Opus costs $5.00 standard, $0.50 cached. And Gemini 3.1 Pro? $3.60 for a 1M request. Only 28% cheaper than Opus, not the 2.5x cheaper that the headline pricing suggests.
At the context sizes this article is about, the Gemini price advantage is marginal. And if an Opus agent completes the task in one run while a cheaper model needs retries with human intervention, the effective cost flips entirely. For our full pricing breakdown across all models, check the LLM pricing comparison.
The Caching Angle#
If you're resending the same context (conversation history, codebase, document set), caching flips the economics:
- Flash-Lite cached: $0.025/1M. You can process 1M tokens of context for less than the cost of a piece of gum.
- Gemini 3.1 Pro cached: $0.20/1M under 200K, but $0.40/1M over 200K. The gap with Claude narrows here too.
- Opus cached: $0.50/1M. Only 25% more than Gemini's long-context cached rate. Makes repeated agentic calls over the same codebase very affordable.
Real-World Use Cases for 1 Million Tokens#
Full Codebase Analysis With Claude Code#
This is where I spend most of my time. Claude Code with Opus 4.6 and 1M context loads your entire codebase into context. Not file-by-file. The whole thing. Then it reasons across files, understands architectural patterns, and makes changes that account for dependencies you forgot existed.
If you haven't set it up yet, my definitive guide to Claude Code covers everything.
Customer Conversation History#
Load 6 months of a customer's support tickets, chat transcripts, and product usage data into context. Ask the model to draft a personalized retention offer. With 200K tokens, you got maybe 2 weeks of history. With 1M, you get the full picture.
This is Opus territory. The reasoning quality at this context length means it actually synthesizes patterns across months of interactions, not just parrots the last few messages.
High-Volume Customer Service Agents#
Telecom companies handle millions of calls daily. Each customer interaction needs their full account history loaded into context. You don't need Opus-level reasoning for "check account balance and explain the latest charge." You need fast, cheap, and good enough.
Gemini 3.1 Flash-Lite at $0.25/1M input with 363 tokens/sec handles this. Load the full customer history, route the request, generate a response. At scale, the cost difference between Flash-Lite and Opus is the difference between a viable product and a burned budget.
Document Summarization and Extraction#
Legal discovery. Insurance claims with 50 attachments. Academic research across hundreds of papers. When the task is "extract and summarize," you don't need the most powerful model. You need the cheapest model that can handle the context.
Flash-Lite for extraction and summarization. Opus if you need to actually reason about what the documents mean.
Personal Knowledge and Journaling#
This is where my Gemini experience started. I loaded journal entries, notes, and personal documents into Gemini's 1M context and asked it questions about patterns in my thinking, recurring themes, connections I missed. The results were genuinely insightful.
Claude does this too now, with better reasoning. But I'll give credit where it's due: Gemini pioneered this use case, and the multimodal angle (loading voice memos, photos, sketches alongside text) is something Claude still can't match.
My Experience: From Gemini's Context Window to Claude's#
Gemini 3 Pro was the first model where 1M context felt genuinely useful. Before that, large context windows existed on paper but the retrieval quality wasn't there. Gemini changed that. I could load my entire journal, ask "what was I worried about in October?", and get an accurate, contextual answer. That was new.
I've been using Gemini 3.1 Pro since it launched. The improvements over 3.0 are real. Better multimodal, faster, slightly better reasoning. For single-turn tasks over large contexts, it's excellent.
But when Claude Opus 4.6 got 1M context, I switched my primary agentic workflows within a week. Not because the context window is better. It's the same size. It's because what Claude does inside that window is fundamentally different.
With Gemini, I can load a codebase and ask questions about it. With Claude, I can load a codebase and have it autonomously refactor it, run tests, fix failures, and commit the changes. Same context, wildly different capability.
For journal insights and lightweight retrieval, I still use Gemini. For anything requiring multi-step reasoning or autonomous actions: Opus, no contest.
Which Should You Choose?#
Choose Claude Opus 4.6 When...#
- You're building agentic workflows that require multi-step tool use and self-correction
- Reasoning quality matters more than cost (legal analysis, complex debugging, strategic decisions)
- You need the highest retrieval accuracy across the full 1M window
- Your agents run coding tasks (Claude Code, autonomous refactoring, bug fixing)
- You need 128K output tokens for long, structured responses
- You want context compaction for effectively infinite conversations
Choose Gemini 3.1 Pro When...#
- You need native multimodal processing (video, audio, images at scale)
- Budget matters and the workload doesn't require peak reasoning ($2 vs $5 per 1M)
- Your pipeline is single-turn, high-volume document processing
- You're building multimodal agents that process diverse media types
- Cached input pricing is critical to your unit economics ($0.20/1M)
Choose Gemini 3.1 Flash-Lite When...#
- You need high-volume agentic tasks at massive scale (telecom, customer service, insurance)
- The task is structured and predictable enough that Opus-level reasoning isn't needed
- Summarization, extraction, and classification over huge documents
- You're building preprocessing pipelines that feed into more powerful models
- Your cost constraint is aggressive and you need 1M context for $0.25 per request
The Smart Play: Route Between All Three#
Don't pick one model. Build a router:
- Flash-Lite for volume: extraction, summarization, classification, structured agentic tasks
- Gemini 3.1 Pro for multimodal and moderate-complexity analysis
- Claude Opus 4.6 for the hard stuff: complex reasoning, critical decisions, agentic coding
Frequently Asked Questions

Enjoyed this post?
Find out which LLM is cheapest for your use case — I test new models as they launch
No spam, unsubscribe anytime.