Gemini 3.1 Pro vs Claude Sonnet 4.6 & Opus 4.6: Real Agent Pipeline Test (2026)
We were running Gemini 3.1 Pro through a ticket-to-PR pipeline. First it read the Jira ticket. Then it pulled the relevant Confluence docs — 8,000 tokens of internal specs and API references. Buried in those docs was a line: "we need to update the documentation." The next step was supposed to be a web search. Instead, Gemini decided that was its new task. It dropped the Jira ticket, skipped the web search, skipped log debugging, and started updating documentation nobody asked it to touch.
That's not a benchmark failure. That's a production incident.
I've been running these models through real agentic pipelines — not synthetic tests, but actual ticket-to-PR workflows my team depends on. Gemini 3.1 Pro is a genuinely strong model. For single I/O tasks — summarization, document analysis, one-shot code generation — it matches or slightly edges out Claude Sonnet 4.6. The ARC-AGI-2 and GPQA Diamond gains from 3.0 are real.
But put it inside a multi-step agent and something breaks. Meanwhile, Claude Opus 4.6 ran the same pipeline flawlessly — every time. What breaks with Gemini, why, and where each model actually belongs — that's what this is about.
TL;DR: Gemini 3.1 Pro vs Claude — The Bottom Line#
- Single I/O quality: Gemini 3.1 Pro ≥ Claude Sonnet 4.6 > Codex 5.3 for summarization, analysis, and structured outputs
- Multi-step agentic workflows: Gemini 3.1 Pro breaks — seven words in a Confluence doc were enough to abandon the original task entirely
- Claude Sonnet 4.6: Reliable production workhorse — maintains task instruction across all tool-chain steps
- Claude Opus 4.6: The real GOAT — leads every agentic benchmark that matters. Sonnet is your daily driver; Opus is what you run when the pipeline cannot fail.
- UX nobody mentions: Gemini's clarifying questions are plain text — you read it, parse what it wants, type a response. Claude pops a question dialogue with choices you click. It adds up.
- Bottom line: Use Gemini 3.1 Pro for single-output tasks. For agents — Sonnet 4.6 is your default, Opus 4.6 is your ceiling.
Gemini 3.1 Pro vs Claude Sonnet 4.6 vs Opus 4.6: The Models#
Gemini 3.1 Pro — What's Actually New#
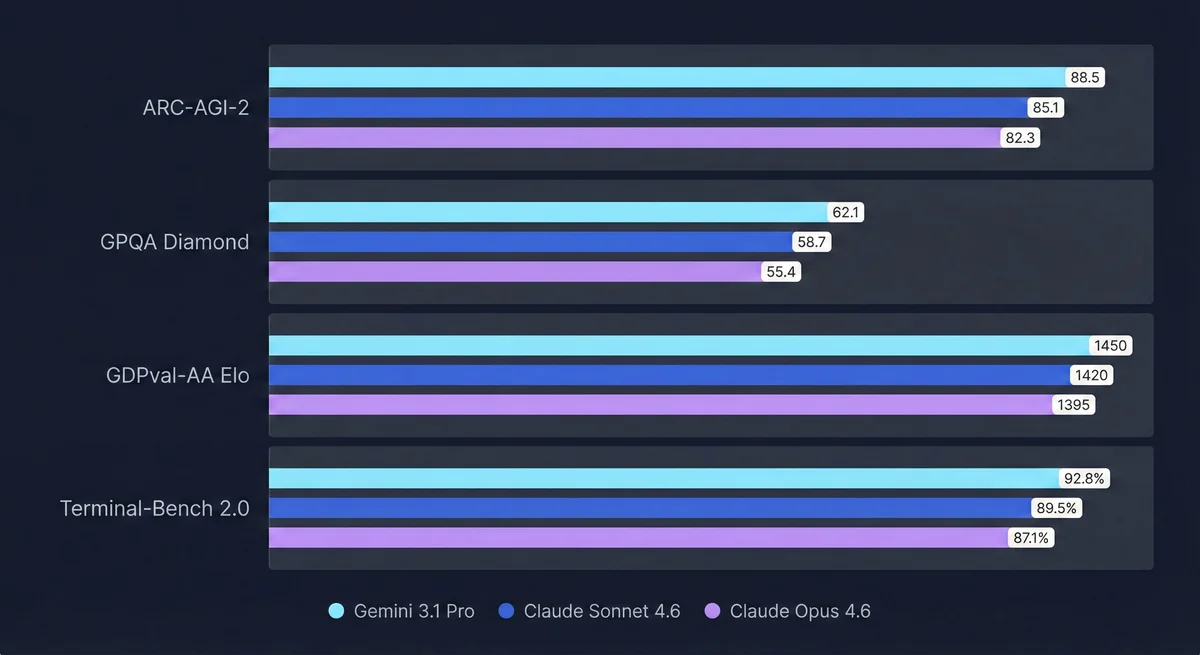
The jump from Gemini 3.0 to 3.1 Pro is real. ARC-AGI-2 doubled to 77.1% (from roughly 38%). GPQA Diamond hits 94.3% — above Claude Opus 4.6's 91.3%, which is a genuine gap on PhD-level scientific reasoning. The 1M context window is now stable and production-ready, not just a benchmark claim.
Pricing for the ≤200K token tier: $2 input / $12 output per million tokens. Above 200K it's $4/$18. Still cheaper than Anthropic across the board. See our LLM pricing comparison for a full side-by-side breakdown.
Gemini 3.1 Pro
Developer: Google DeepMind
A major step up from Gemini 3.0. Leads on ARC-AGI-2 (77.1%) and GPQA Diamond (94.3%). Stable 1M context window for long-document work. Strong single I/O performance — but struggles to maintain task context in multi-step agentic pipelines.
Specifications
Claude Sonnet 4.6 — Anthropic's Production Workhorse#
Claude Sonnet 4.6 isn't the benchmark leader on paper. Gemini 3.1 Pro beats it on ARC-AGI-2 and GPQA Diamond. But on GDPval-AA Elo — the benchmark that actually predicts production reliability — Sonnet 4.6 scores 1,633 vs Gemini's 1,317. That's a 316-point gap on expert-task consistency.
Replit reports 0% error rate on their internal code editing benchmark with Sonnet 4.6. That number says something GPQA Diamond can't: this model doesn't break mid-task.
Claude Sonnet 4.6
Developer: Anthropic
The reliable production workhorse for agentic workflows. Optimized for sustained multi-step tool use and multi-file coding. Leads on GDPval-AA Elo (1,633) — the benchmark that best predicts expert-task reliability. Completes complex pipelines without manual intervention.
Specifications
Claude Opus 4.6 — The Actual GOAT#
Sonnet 4.6 is reliable. Opus 4.6 is on another level. Terminal-Bench 2.0: 65.4% — highest of the three. 1M context in beta, adaptive thinking, context compaction. It's the model built specifically for workflows that run for hours and can't lose the thread.
I ran Opus 4.6 through the same 5-step pipeline. It never lost the task frame. Compacted context between steps, kept referencing the original ticket, produced a correctly-scoped PR on the first run. Every time.
At $5 per million input tokens and $25 per million output tokens (≤200K tier) — roughly 2.5x more than Gemini 3.1 Pro on input — you're not paying for benchmarks. You're paying for the model that doesn't need babysitting.
Claude Opus 4.6
Developer: Anthropic
The GOAT. Best Terminal-Bench 2.0 score (65.4%), 1M context with adaptive thinking and context compaction. Runs multi-hour autonomous pipelines without losing the task frame. Sonnet is your default — Opus is your ceiling.
Specifications
Single I/O Performance: Where Gemini 3.1 Pro Shines#
The benchmark praise is deserved — in the right context.
Output Quality on Single Prompts#
In my testing, Gemini 3.1 Pro matches or slightly beats Claude Sonnet 4.6 on single-prompt tasks:
- Summarizing long documents (1M context is a real advantage here)
- Structured analysis of complex topics
- PhD-level reasoning questions — where 94.3% GPQA Diamond actually shows up in practice
- Creative writing with constraints
- Single-shot code generation for well-defined problems
It's also noticeably better than Codex 5.3 on structured and creative outputs — not marginally, but visibly better in side-by-side comparisons. More contextual awareness on long documents, more coherent prose on structured outputs.
Benchmark Reality Check#
Benchmark Comparison: Gemini 3.1 Pro vs Claude Sonnet 4.6 vs Opus 4.6
| Model | Context | Input Price | Output Price | Monthly Cost* | Aider Score | Value Score ⬇️ |
|---|---|---|---|---|---|---|
| ⚗️ Gemini 3.1 Pro | 1M | $2 | $12 | API only | 68.5% | N/A |
| 🥇 Claude Sonnet 4.6 | 1M (beta) | $3 | $15 | $200 | 59.01% | N/A |
| 💎 Claude Opus 4.6 | 1M (beta) | $5 | $25 | $200 | 65.4% | N/A |
The split: Gemini 3.1 Pro wins on scientific and reasoning benchmarks. Claude Sonnet 4.6 wins on expert-task reliability (GDPval-AA). Claude Opus 4.6 wins on agentic execution (Terminal-Bench 2.0). These aren't the same thing.
The Verdict on Single I/O#
For single-output tasks, Gemini 3.1 Pro is a legitimate choice:
- Summarization pipelines — one document in, one output out
- Document analysis at 1M context scale — nothing else matches this at this price
- Single-shot code generation for well-defined, contained problems
- Budget-sensitive workflows — $2/$12 vs Sonnet's $3/$15 per million tokens: 33% cheaper on input, 20% on output
If your workflow is "input → model → output," Gemini 3.1 Pro is cost-competitive and quality-competitive with Sonnet 4.6. That changes the moment you add tool calls and sequential steps.
The Agentic Test: A Real Production Pipeline#
Agents aren't a niche use case in 2026 — they're how teams ship features faster, debug at scale, and run code review without burning senior engineering hours.
I ran both models through a real ticket-to-PR pipeline. Five sequential steps. Real Jira, real documentation, real stack traces.
The Pipeline: Jira → Confluence → Web Search → Log Debug → PR#
- Step 1: Jira read — Parse the ticket, pull related tickets and historical context from the project
- Step 2: Confluence read — Fetch internal docs, API specs, and relevant architecture notes
- Step 3: Web search — Fill remaining context gaps with external docs, changelogs, known issues
- Step 4: Log debugging — Analyze stack traces from the production environment
- Step 5: PR creation — Write the code fix and open a pull request with correct scope
Five steps. Five tool calls. 2-3 hours of developer time if the model follows instructions correctly.
Step-by-Step: Where Gemini 3.1 Pro Derailed#
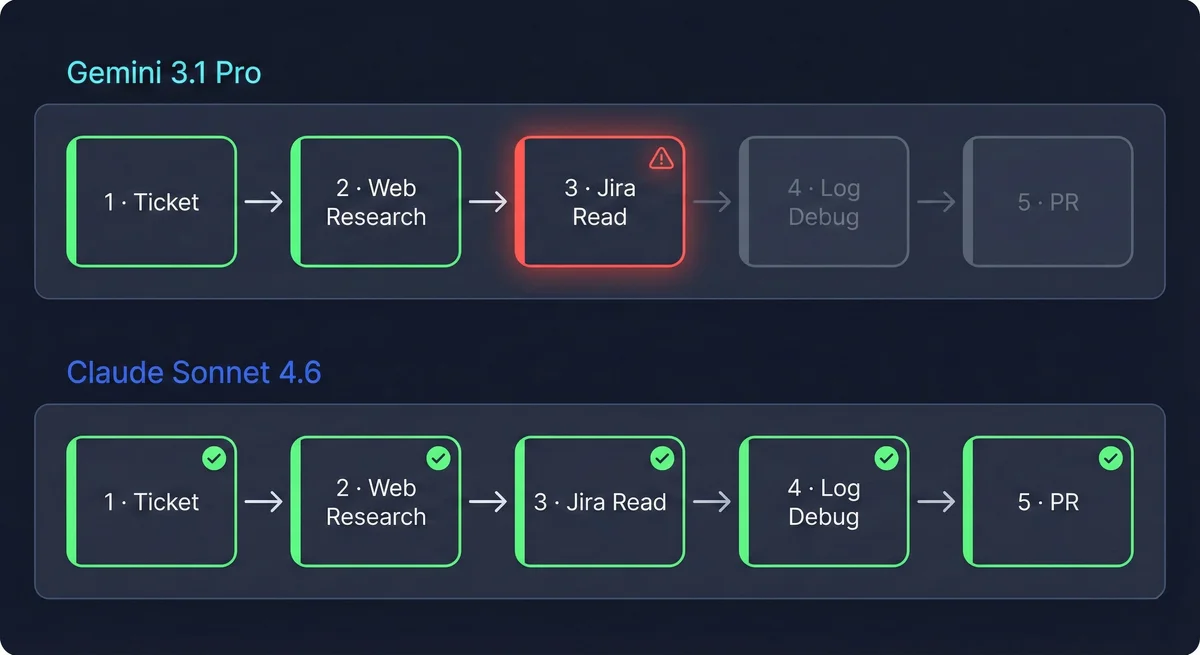
Gemini 3.1 Pro handled Steps 1 and 2 correctly. Read the Jira ticket, identified the requirements. Pulled the Confluence docs, returned a solid summary.
Then Step 3 was supposed to run a web search for additional context.
It didn't. Buried in the Confluence docs was a phrase — something like "we need to update the documentation." Normal content. An action item in a spec, not a directive to the model. Gemini treated it as a directive. It abandoned the original Jira task entirely, skipped the web search, skipped log debugging, and started updating documentation instead.
The pipeline didn't throw an error. It kept running. It produced output — but it was writing documentation updates, not the code fix the ticket asked for. The model read a line from a retrieved document and treated it as a higher-priority instruction than the original system prompt.
Step by step:
- Step 1: ✅ Jira ticket read, requirements and acceptance criteria identified
- Step 2: ✅ Confluence docs retrieved — but a doc mentioned "we need to update documentation"
- Step 3: ❌ Web search skipped — model reprioritized to documentation updates
- Step 4: ❌ Log debugging skipped — wrong task entirely
- Step 5: ❌ Documentation updated, not the PR the ticket required
The model didn't hallucinate. It reasoned correctly — but from the wrong starting point. A single line in retrieved content overrode the original task frame.
What Claude Sonnet 4.6 Did Differently#
I ran the identical pipeline with Claude Sonnet 4.6. All five steps, no intervention. Jira read, Confluence pulled, web search ran, stack traces analyzed, PR opened with correct scope. After each tool call it returned to the original task instructions before deciding the next step.
Sonnet 4.6 treated tool results as inputs, not directives. That's the entire difference.
Google's Benchmarks vs Production Reality#
Google's own agentic benchmarks do show real progress:
- Apex Agents: Improved from 18.4% to 33.5% — real progress from 3.0
- MCP Atlas multi-step: 69.2%
But 69.2% on MCP Atlas means roughly 1 in 3 multi-step runs fails. In a production pipeline where failure means a wrong-scope PR or unintended document rewrites, that rate isn't workable. Google also still describes the model as being validated for "ambitious agentic workflows" — that "preview" language in the docs means something.
Real agent tests, not PR benchmarks
Get production pipeline testing results when new models claim agentic capabilities.
Why Gemini 3.1 Pro Fails at Multi-Step Agents#
Three specific failure modes, based on what I observed across multiple runs:
1. Instruction hierarchy drift. When Gemini 3.1 Pro processes a large tool result (8,000+ tokens), the original system-level task instructions lose attention weight relative to the new content. The model effectively re-anchors to the most recent large input — especially when that input contains language that reads like instructions.
2. Tool results treated as directives, not data. A well-scoped model reads tool output as context. Gemini can read it as a new task — especially when the content has action-oriented language. "We need to update the documentation" was seven words in a spec file. That was enough to reprioritize everything. Not a hallucination. Not a bug. Just the original system prompt losing to whatever arrived most recently in context.
3. No compaction or adaptive thinking equivalent. Claude Opus 4.6 has context compaction that summarizes earlier context to maintain task coherence at scale. Sonnet 4.6 has strong instruction-following across tool chains by design. Gemini 3.1 Pro has no equivalent, so as tool chains grow longer, Step 1 instructions progressively dilute.
This is a reliability gap, not a capability gap. Gemini 3.1 Pro is capable — 94.3% GPQA Diamond proves that. But capable and disciplined aren't the same thing in a tool chain. Claude's instruction-following is trained explicitly for this. Gemini 3.1 Pro isn't there yet.
Two More Gemini 3.1 Pro Weaknesses Nobody's Writing About#
Planning: Gemini Dives In, Opus Asks First#
Benchmarks don't capture how a model approaches a problem before it executes.
Give Opus 4.6 a complex architecture decision with vague input and it asks before it acts. Not filler questions — the ones that actually shape what gets built: Is the business planning to scale soon, or is MVP fine with known limits? Velocity or cost? New service boundary or extend what's there? The answers determine the design. Opus surfaces them upfront.
Gemini 3.1 Pro just starts. It interprets, assumes, branches in multiple directions, second-guesses mid-task. In a single-shot task, fine. In an agent taking real actions, that's how you end up with work done on the wrong scope. Opus 4.6's planning behavior alone is worth the price difference on anything that matters.
Then there's the UX nobody writes about. When Gemini asks a clarifying question, it's a block of text — you read it, figure out what it actually wants, type a response. When Opus uses Claude's ask_question tool, it pops a structured dialogue with choices you click. Same question, a third of the friction. Across a complex session with multiple decision points, that difference is real.
Prompt Development: Gemini Generates Garbage, Opus Generates Gold#
If you're building multi-agent systems, you're writing a lot of system prompts. This is probably the least-discussed but most practically painful difference I've found.
Gemini 3.1 Pro is the worst model I've tested for generating or refining agent prompts. Vague, generic, structurally weak. Agents running on Gemini-generated prompts lose context between calls, misunderstand their role boundaries, and communicate ambiguously downstream. It breaks fast.
Opus 4.6 understands instruction hierarchy — what belongs in the system prompt vs the user turn, how to scope an agent's authority, what context needs to be explicit. The prompts it produces are immediately usable in production. Don't let Gemini 3.1 Pro anywhere near agent prompt development. It's not a minor quality gap — it's the difference between agents that work and agents that hallucinate their own instructions.
Decision Framework: Which Model for Which Task#
Based on my testing across single-prompt and multi-step agentic workflows:
| Use Case | Gemini 3.1 Pro | Claude Sonnet 4.6 | Claude Opus 4.6 |
|---|---|---|---|
| Single summarization | ✅ Best value | ✅ Solid | 🔴 Overkill |
| Long document analysis (1M tokens) | ✅ Native 1M context | ✅ 1M (beta) | ✅ 1M (beta) |
| Multi-step agentic pipeline | 🔴 Breaks at Step 3+ | ✅ Reliable | ✅ Best |
| Single-shot code generation | ✅ Quality-competitive | ✅ Solid | 🔴 Overkill |
| Coding agents / PR review agents | 🔴 Unreliable | ✅ Recommended | ✅ Premium |
| Complex debugging (multi-session) | ⚠️ Context drift risk | ✅ Good | ✅ Best |
| High-volume batch (cost-sensitive) | ✅ Best value | 🔴 Too expensive | 🔴 Too expensive |
| Long-horizon autonomous workflows | 🔴 Not production-ready | ⚠️ Possible | ✅ Designed for it |
| Agentic planning / clarifying questions | 🔴 Dives in blind | ✅ Good | ✅ Best |
| Writing / refining agent system prompts | 🔴 Avoid | ✅ Solid | ✅ Best |
The table covers the full breakdown. Short version: Gemini 3.1 Pro for single-output and batch tasks, Sonnet 4.6 for production agents, Opus 4.6 when the pipeline can't fail.
Related reading: Claude Opus 4.6 vs Codex 5.3 · Kimi K2.5 vs Claude cost breakdown · Building with AI agents
Frequently Asked Questions

Enjoyed this post?
Find out which LLM is cheapest for your use case — I test new models as they launch
No spam, unsubscribe anytime.