GLM-5 vs Kimi K2.5 vs Claude Sonnet 4.6: Real Testing Results (2026)

February 12, 2026. Zhipu AI dropped GLM-5 with bold claims: a "Kimi K2.5 killer" with 744B parameters, an MIT license, and API pricing starting at $0.80 per million tokens. The benchmarks looked real. I plugged it into my OpenClaw agentic workflows the same day.
Two weeks later, here's the verdict: the benchmarks are real. The marketing isn't.
TL;DR#
- GLM-5 actually beats Kimi K2.5 on benchmarks (Intelligence Index 50 vs 47, SWE-bench 77.8% vs 76.8%) — the marketing claims aren't fabricated
- Real-world agentic workflows tell a different story — z.ai capacity issues and complex task loop failures undermine the numbers
- Kimi K2.5's PARL Agent Swarm still wins for multi-step autonomous work, despite the lower benchmark scores
- Claude Sonnet 4.6 operates in a different category — not a budget question, a professional tooling question
- Don't switch to GLM-5 based on marketing — benchmark wins don't equal workflow wins
Meet the Contenders#
GLM-5: Zhipu AI's Open-Source Challenger#
Released February 12, 2026, GLM-5 is Zhipu AI's most capable open-source model. At 744B total parameters with only 40B active at inference time (Mixture-of-Experts architecture), the inference cost stays reasonable. The MIT license is the real story — you can self-host it, fine-tune it, and deploy it without usage restrictions.
GLM-5
Developer: Zhipu AI / Z.ai
Open-source frontier model optimized for agentic engineering and long-horizon tasks. MIT license enables self-hosting and fine-tuning. Competitive benchmarks, but real-world performance depends heavily on your provider.
Specifications
Kimi K2.5: The Agentic Workflow Standard#
Kimi K2.5 from Moonshot AI landed January 27, 2026, and it changed the conversation around budget AI for agentic work. At 1 trillion parameters (with 32B active), it's the largest open-weight model available by parameter count. The real differentiator is the training: PARL (Parallel-Agent Reinforcement Learning), a framework that teaches the model to decompose tasks and delegate to parallel sub-agents. If you've been using it for OpenClaw workflows, you've already seen why this matters.
Kimi K2.5
Developer: Moonshot AI
Reasoning-focused model with PARL Agent Swarm capabilities. The best open-weight model for autonomous agentic workflows. Larger context window than GLM-5, with genuine parallel execution for research and multi-step tasks.
Specifications
Claude Sonnet 4.6: The Professional Developer's Choice#
Claude Sonnet 4.6 is Anthropic's current flagship for daily development work — faster than Opus, smarter than earlier Sonnet versions, and built into Claude Code. If you've read my earlier Claude Sonnet vs Kimi comparison, the 4.6 iteration continues the same story: unmatched ecosystem, premium quality, premium price.
Claude Sonnet 4.6
Developer: Anthropic
Professional developer's daily driver with native Claude Code integration, MCP ecosystem, and extended thinking. Intelligence Index 51 leads all three contenders. The $200/mo subscription covers unlimited Claude Code use — API pricing is separate.
Specifications
What the Benchmarks Actually Say#
Here's the thing: GLM-5's marketing claims are largely backed by real numbers.
GLM-5's Official Numbers (from z.ai)#
Zhipu AI published a full benchmark table in their launch post. The headline numbers:
- SWE-bench Verified: GLM-5 77.8% vs Kimi K2.5 76.8% vs Claude Opus 4.5 80.9% — GLM-5 leads open-source
- VendingBench 2 (long-horizon business simulation): GLM-5 $4,432 vs Claude Sonnet 4.5 $3,849 vs Kimi $1,198 — GLM-5 leads, Kimi trails badly
- Terminal-Bench 2.0: GLM-5 56.2% vs Kimi 50.8% vs Claude 59.3%
- MCP-Atlas (tool use): GLM-5 67.8 vs Kimi 63.8
- HLE with Tools (knowledge): Kimi 51.8% vs GLM-5 50.4% — Kimi edges ahead here
On paper, the "Kimi Killer" label isn't unfair. GLM-5 is ahead on 4 out of 5 major benchmarks.
The Independent Numbers (ArtificialAnalysis)#
ArtificialAnalysis runs independent benchmark tests on dedicated hardware. Their data:
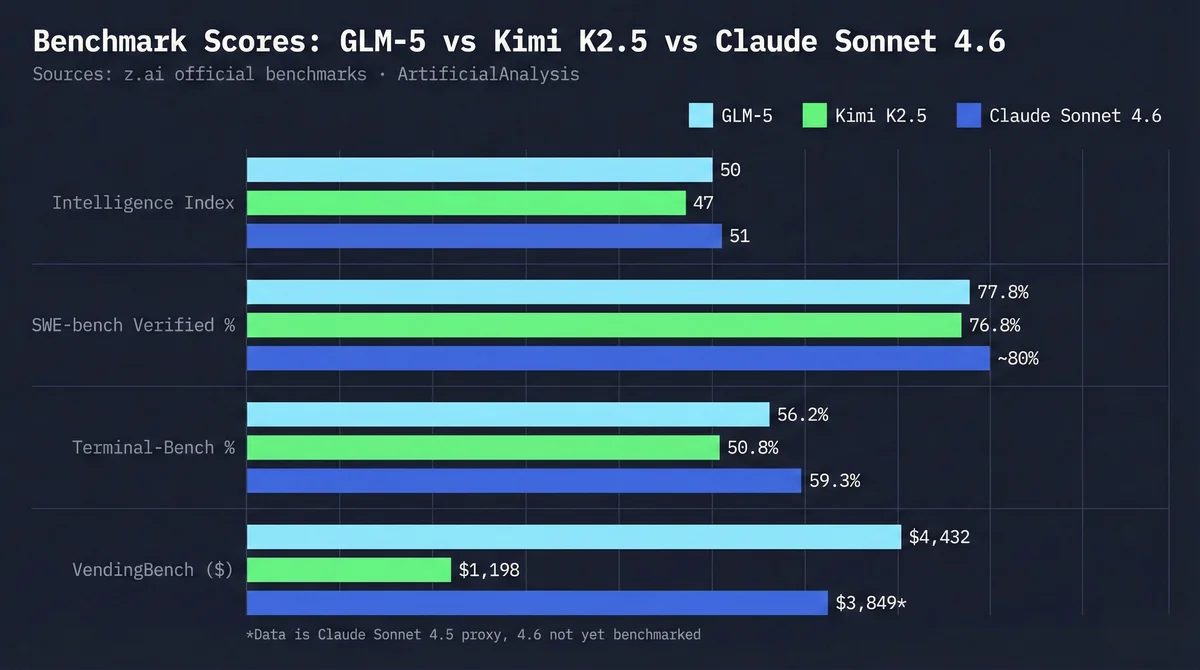
Model Performance: GLM-5 vs Kimi K2.5 vs Claude Sonnet 4.6
| Model | Context | Input Price | Output Price | Monthly Cost* | Aider Score | Value Score ⬇️ |
|---|---|---|---|---|---|---|
| 🥇 Claude Sonnet 4.6 | 200K | $3.00 | $15.00 | $200 | ~80%+ | 51 |
| 🥈 GLM-5 | 200K | $0.80 | $2.56 | ~$20 | 77.8% | 50 |
| 🥉 Kimi K2.5 | 256K | $0.60 | $3.00 | $60 | 76.8% | 47 |
Claude Sonnet 4.6 leads, GLM-5 edges ahead of Kimi on benchmarks, and all three trail Claude Opus 4.5 on the hardest tasks.
Why Benchmark Wins Don't Tell the Full Story#
Here's what the benchmark table can't capture: benchmarks test discrete, isolated tasks. Agentic work is continuous multi-step execution.
VendingBench 2 shows GLM-5 excels at a structured long-horizon task. But running a simulated vending machine business is very different from an OpenClaw agent that needs to navigate real file systems, make tool calls, debug its own errors, and recover from unexpected states — all while staying coherent across 50+ steps.
The other thing benchmarks miss: provider capacity. GLM-5 theoretically hits 70 tokens/second. In practice, z.ai's infrastructure doesn't deliver that consistently.
Real-World Testing: Agentic Workflows in OpenClaw#
I ran both models on the same OpenClaw setup for two weeks. Same tasks, same configuration, same prompts — only the model changes.
Testing Methodology#
- Tasks: Code refactoring (multi-file), autonomous PR creation, research + implementation workflows, TDD with spec files
- Environment: OpenClaw with identical configs on both models
- Evaluation: Task completion rate, loop detection, output quality, wall-clock time
Where GLM-5 Failed: The Loop Problem#
The most consistent failure mode with GLM-5: complex logic with interdependencies causes infinite loops.
One Reddit r/opencodeCLI user described it perfectly: "when I provide them a plan with a TDD suite, their reliability becomes a problem. They can finish simple tasks, but anything with a more complex logic puts them in a loop with no escape."
In my testing, this showed up on multi-file refactors where changes in one file required corresponding changes in 3+ other files. GLM-5 would fix file A, then fix file B incorrectly, then attempt to fix file A again, and loop. After 45 minutes and a lot of wasted tokens, the task was incomplete.
Kimi K2.5 handled the same task in 12 minutes with clean output. The PARL swarm framework — where an orchestrator delegates to parallel sub-agents — is genuinely better for this class of task.
The Speed Paradox: 70 tok/s on Paper, Painful in Practice#

The r/opencodeCLI community has flagged this repeatedly: "GLM 5 is currently the only open source model that I find to actually be competitive with frontier models... it's a shame that in z.ai is too slow."
The spec says 70 tokens/second. The reality during peak hours on z.ai is closer to 15-25 tokens/second. For an agentic workflow that runs 200+ tool calls, this compounds into minutes of added latency per task.
SiliconFlow is the recommended alternative provider (cheaper, faster), but it adds setup friction. You need to configure your OpenClaw provider settings, test the integration, and accept that you're now depending on a third-party relay. For most developers, that friction erases the cost advantage.
There's also the Claude Code issue. Some developers try to route GLM-5 through the Claude Code interface. As one Reddit commenter noted: "you lose all the integrated features Claude Code gives you." The file explorer, project context, memory, shortcuts — all gone. You get a raw API call wearing a familiar UI.
Why Kimi K2.5's PARL Swarm Still Wins#
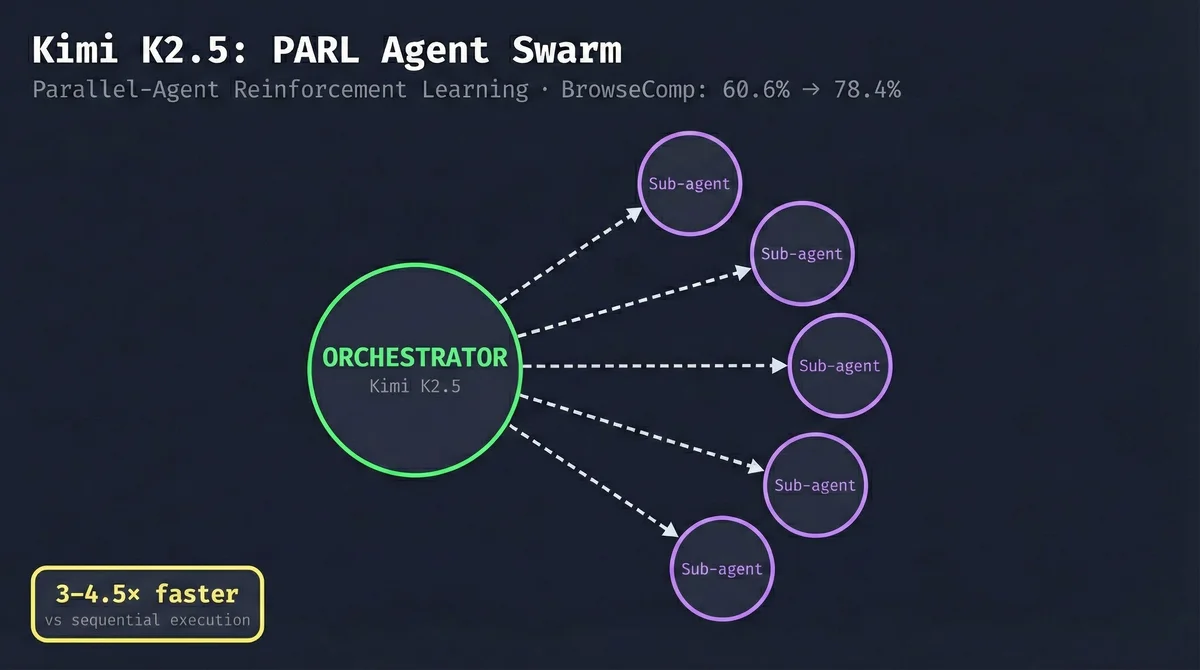
The key technical innovation in Kimi K2.5 is PARL — Parallel-Agent Reinforcement Learning. Instead of executing tasks sequentially (tool call → observe → reason → next call), the orchestrator learns to decompose problems into parallelizable subtasks and delegate to frozen sub-agent copies.
The numbers from Moonshot AI:
- BrowseComp: 60.6% (single agent) → 78.4% (PARL swarm)
- Research + execution tasks: 3-4.5x faster with parallel execution
- WideSearch F1: 72.7% → 79.0% with swarm
For research-heavy agentic tasks — the kind where you need to gather information from multiple sources before implementing — this matters a lot. Kimi's swarm can run four parallel research sub-agents while the orchestrator waits, then synthesize and implement. GLM-5 does this sequentially.
Following the GLM-5 vs Kimi debate?
I test new models the week they drop. Get real-world results — not benchmark marketing — in your inbox.
Where GLM-5 Actually Holds Its Own#
GLM-5 isn't a bad model. It has real strengths:
- Simple, direct single-file tasks: Comparable to Kimi, sometimes faster
- Agent orchestration: Works well as an orchestrator for simpler multi-agent setups
- Self-hosted deployments: The MIT license is genuine value if you need local inference
- Long-horizon planning in constrained environments: VendingBench results suggest real capability here
If you need to self-host a capable model and can tolerate the setup complexity, GLM-5 is the best option available. Kimi K2.5 is not self-hostable in the same way.
Development Work: Claude Sonnet 4.6's Domain#
Claude Sonnet 4.6 and GLM-5/Kimi K2.5 are not in the same category. Worth saying upfront.
Why Claude Sonnet 4.6 Is Not Just Another API#
Routing GLM-5 through Claude Code to "save money" misses what you'd actually be giving up. Claude Sonnet 4.6 isn't just a model — it's a model built into a professional development environment with:
- Native file system access and project memory
- Extended thinking mode for complex problems
- First-class MCP (Model Context Protocol) support
- Persistent conversation context across sessions
- Anthropic's ongoing fine-tuning for coding specifically
The Claude Code ecosystem is why Intelligence Index 51 means more than a 1-point lead over GLM-5's 50. The model was built for this environment — not retrofitted into it.
The Ecosystem Advantage Nobody Mentions#
If you've spent any time with the Claude Code setup and CLAUDE.md configuration, you know the depth of the tooling. Keyboard shortcuts, slash commands, project-level memory files, MCP server integrations — this is a professional development environment, not just an API wrapper.
GLM-5 via API gives you a capable model. Claude Sonnet 4.6 via Claude Code gives you a capable model inside a system built for your daily workflow.
Code Quality vs Cost: The Real Math#
The $200/month Claude subscription covers unlimited Claude Code use. For a developer spending 8 hours/day in Claude Code, that works out to roughly $1.25/hour of AI assistance.
Compare that to GLM-5 at ~$20/month but with more rework: one 45-minute loop failure (like the one I described above) costs more in your time than a month of the price difference between GLM-5 and Claude.
The math changes if you're building products and charging API costs to customers. In that case, the per-token price matters and GLM-5's $0.80 input rate is genuinely attractive. Compare all per-token rates in our LLM pricing comparison.
Coding Performance: GLM-5 vs Kimi K2.5 vs Claude Sonnet 4.6
| Model | Context | Input Price | Output Price | Monthly Cost* | Aider Score | Value Score ⬇️ |
|---|---|---|---|---|---|---|
| 🥇 Claude Sonnet 4.6 | 200K | $3.00 | $15.00 | $200 | Best | Native IDE |
| 🥈 Kimi K2.5 | 256K | $0.60 | $3.00 | $60 | Strong | OpenClaw |
| 🥉 GLM-5 | 200K | $0.80 | $2.56 | ~$20 | Good | Any IDE (API) |
Pricing Deep Dive: The Real Monthly Cost#
GLM-5: $15-25/Month (Hidden Costs Apply)#
At $0.80 input / $2.56 output per million tokens on z.ai, GLM-5 looks like the obvious budget choice. A typical developer running ~5M input tokens and ~2M output tokens monthly pays around $19/month.
Here's the problem: that estimate assumes your tokens produce working output. Loop failures waste tokens. Quality degradation on complex tasks means you run tasks multiple times. In my testing, GLM-5's real effective cost was closer to 1.5x the token estimate once rework is factored in.
SiliconFlow pricing is slightly different and generally faster — worth checking if you're committed to GLM-5.
Kimi K2.5: $19-60/Month All-In#
Synthetic.new offers two tiers: Standard at $19/month and Pro at $60/month (1,350 req/5hrs — more rate limit headroom than Claude's $200 tier). For serious agentic work, the Pro tier is the right choice: higher reliability on complex tasks means your tokens actually produce the output you need. Less rework = better effective cost.
For API-only access via OpenCode, you're looking at $0.60/M input and $3.00/M output — comparable input to GLM-5, higher output. With higher first-pass success rates, effective cost per completed task tends to be lower.
Claude Sonnet 4.6: $200/Month — Is It Worth It?#
The Max plan gives you unlimited Claude Code access plus generous API credits. For a professional developer, this is the most defensible expense in the AI tooling stack — more than Cursor, more than GitHub Copilot.
If you're shipping code that matters and your time is worth anything above $50/hour, the productivity difference between Claude and the budget alternatives covers the $140/month premium inside the first week. If you're a student, hobbyist, or building a side project where time isn't monetized, the math is different.
Monthly Cost Calculator: GLM-5 vs Kimi K2.5 vs Claude Sonnet 4.6
The Hidden Cost: Your Time#
Lower token price plus more rework does not equal cheaper. One 45-minute loop failure on a task that Kimi would have completed in 12 minutes costs you 33 minutes. At $100/hour developer time, that's $55 of productivity lost — more than 2 months of the price difference between GLM-5 and Kimi K2.5.
Token-price comparisons never include this.
Feature-by-Feature Comparison#
GLM-5 vs Kimi K2.5 vs Claude Sonnet 4.6: Full Comparison
| Feature | GLM-5 | Kimi K2.5 | Claude Sonnet 4.6 |
|---|---|---|---|
| Context Window | 200K tokens | 256K tokens | 200K tokens |
| API Pricing (input) | $0.80/M | $0.60/M | $3.00/M |
| Monthly (subscription) | ~$20 | $19-60 | $200 |
| Intelligence Index | 50 | 47 | 51 |
| SWE-bench Verified | 77.8% | 76.8% | ~80%+ |
| Speed (spec) | 70 tok/s | 45 tok/s | 58 tok/s |
| Speed (real) | 15-25 tok/s | 40-45 tok/s | 55-58 tok/s |
| Multi-step agentic | Loop-prone | PARL swarm | Reliable |
| Long-horizon tasks | Strong (VendingBench) | Moderate | Strong |
| IDE integration | Any (via API) | OpenClaw/API | Native Claude Code |
| Open source | Yes (MIT) | Yes (Apache-2.0) | No |
| Self-hostable | Yes | Partially (large) | No |
| Hallucination risk | Low | Medium (AA: -11) | Low |
Decision Framework#
Choose GLM-5 If...#
- Self-hosting is a hard requirement — MIT license + reasonable hardware requirements make this the best open-source option
- You're building products that pass API costs to customers — $0.80/M input is genuinely attractive at scale
- Simple, direct coding tasks where loop failures are unlikely (single-file, well-specified tasks)
- You've exhausted Kimi K2.5 and want to experiment with alternatives
Even in these scenarios, test Kimi K2.5 first. For most developers, the reliability difference is worth the price premium.
Choose Kimi K2.5 If...#
- Agentic workflows are your primary use case — OpenClaw, multi-step tasks, research + implementation
- You're budget-conscious but quality matters — $19-60/mo is the sweet spot where reliability doesn't require $200/mo premium
- Research + execution tasks where the PARL swarm's parallel execution saves significant time
- You're already using OpenClaw and want the best-supported budget model for it
For most developers in the sub-$200 tier, this is where you should land.
Choose Claude Sonnet 4.6 If...#
- You're a professional developer using Claude Code daily — the ecosystem value alone justifies $200/mo
- Code quality and correctness matter more than token cost — production software, client work, anything where bugs are expensive
- You need the full MCP + memory + extended thinking stack — no open-source model replicates this
- $200/mo is justified by your productivity — for most professional developers, it is
For a deeper look at how Claude Sonnet compares on agentic tasks, my Claude Opus 4.6 vs Codex 5.3 comparison covers that territory well.
The Honest Verdict#
On benchmarks: GLM-5 wins vs Kimi K2.5. That's the honest truth. Intelligence Index 50 vs 47, SWE-bench 77.8% vs 76.8%, Terminal-Bench 56.2% vs 50.8%. If you only look at the numbers, the "Kimi Killer" label is defensible.
In practice: Kimi K2.5 wins for agentic workflows. The PARL swarm delivers real parallel execution. The z.ai capacity issues make GLM-5's theoretical speed advantage meaningless. The loop failures on complex tasks cost more in developer time than the token savings.
For professional development: Claude Sonnet 4.6 operates in a different category entirely. The Intelligence Index lead (51 vs 50) understates the actual advantage — the ecosystem, the native tooling, the reliability are compounding advantages that don't show up in any benchmark.
Bottom line: Don't switch to GLM-5 based on the marketing. The "Kimi Killer" hasn't landed yet. Give it six months — z.ai will likely fix the capacity issues and the model's core quality is genuinely competitive. But for production agentic work today, Kimi K2.5 is still the standard.
Frequently Asked Questions

Enjoyed this post?
Find out which LLM is cheapest for your use case — I test new models as they launch
No spam, unsubscribe anytime.


